Метод на Шенън-Фано
Независимо и едновременно е предложен от Клод Шенън (Bell Labs) и Р.М. Фано (MIT).
 |
Шенън-Фано Методът изисква да са известни вероятностите за срещането на всеки един символ в съобщението. На базата на тези вероятности се конструира таблица със следните характеристики: - всеки символ се представя чрез код - различните кодове имат различен брой битове - кодовете за символи с по-ниска вероятност имат повече битове от тези с по-висока вероятност - кодовете могат еднозначно да бъдат декодирани в символи |
Алгоритъмът за конструриарне на таблицата работи по следния начин:
1. За симовлите се създава таблица с вероятността за тяхното срещане.
2. Таблицата се сортира според честотата на срещане, като символите с най-голяма вероятност са в началото на списъка.
3. Таблицата се разделя на две части, като броят на всички срещания на символите в първата й част е максимално близък до броя на всички срещания на символите от втората част.
4. При генерирането на кода на символите от първата част се присвоява нула, а на тези от втората част – единица.
5. Алгоритъмът се прилага рекурсивно, докато във всяка група остане само един символ.
 |
Пример Нека имам следните символи и техните вероятности
Използвайки алгоритъма получаваме следните кодове:
|
След получаването на таблицата с кодове, пристъпваме към конструриране на декодиращото дърво на Шенън-Фано. То се използва, за да можем еднозначно да извличаме символи от потока входящи битове. За получената таблица със символи и кодове, декодиращото дърво изглежда така:
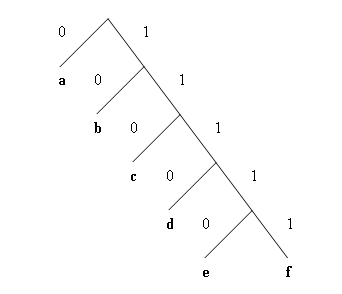
 |
ВАЖНО При алгоритъма на Шенън-Фано има един основен проблем. В случай на почти равно разделяне на групите по вероятности е възможно да възникнат две възможности, за конструиране на таблицата, което води до пораждане на различни дървета. |
| |
Пример Нека имаме следната таблица с вероятности
Възможните таблици с кодове в случая са: Таблица 1
Таблица 2
Таблица 3
|
| |
Цена на кода Цена на кода се нарича величината, показваща средния брой битове необходими за кодирането на произволна буква от входното съобщение. Цената на кода се изчислява като
Където: li ( 1 ≤ i ≤ n ) е дължината на кода на буквата ai
pi е вероятността за срещане на ai |
| |
Оптимален код Когато L приема минимална стойност, казваме че кодът строи оптимален подбуквен код за фиксирана азбука { a1, a2, ... an } с фиксирани честоти на срещане { p1, p2, ... pn } |
Нека α е произволно входно съобщение с дължина d(α) (в брой букви). Тогава
| d(α) | n ∑ i = 1 |
li.pi |
ще бъде дължината (като очакван брой битове) на кодираното съобщение.
В нашия случай можем да изчислим очакваната дължина на съобщенията L1, L2, L3 съответно за Таблица 1, 2 и 3.
L1 = 2.0,2 + 2.0,2 + 3.0,2 + 3.0,15 + 3.0,15 + 3.0,10 = 2,60 бита
L2 = 2.0,2 + 3.0,2 + 3.0,2 + 2.0,15 + 3.0,15 + 3.0,10 = 2,65 бита
L3 = 3.0,2 + 3.0,2 + 2.0,2 + 2.0,15 + 3.0,15 + 3.0,15 = 2,65 бита
| |
ВАЖНО От L1< L2 и L3 следва един много важен извод: Алгоритъмът на Шенън-Фано не винаги строи оптимални кодове. |